2023-08-15 Packet Loss and High Latency on GRR server (Resolved)

Written by Kevin Dutkiewicz
Updated at September 29th, 2023
Table of Contents
Event Description: Packet Loss and High Latency on GRR server
Event Start Time: 2023-08-15 12:30 EDT
Event End Time: 2023-08-16 17:00 EDT
RFO Issue Date: 2023-08-17
Affected Services:
- All services from core server GRR
Event Summary
High packet loss and unreliable communication using the GRR server.
Event Timeline
August 15, 2023
11:00 EDT - Started receiving multiple reports of phones cutting in and out and poor quality. Client tickets submitted and reports from Discord.
12:00 EDT - All available resources from OIT gathered to start troubleshooting
12:30 EDT - Official start of Major Incident - ticket INC-000000016
12:47 EDT - Announcement in Discord - "OIT_Steven (CSE Engineer) — 08/15/2023 12:47 PM
As of 12:00p EST on August 15, 2023 we became aware of call quality concerns for phones registered to the GRR and LAS servers.
Symptoms include but are not limited to calls cutting in and out, possible call dropping, and garbled audio.
We have engaged the DC support for further investigation and is marked with the highest urgency."
14:03 EDT - Announcement in Discord - "oit_marissa (Chief of Staff) — 08/15/2023 2:03 PM
Major Incident Update: We are continuing to investigate the cause for the increased latency to GRR and LAS with DC support. At this time the cause is unknown. Users on GRR experiencing loss of call quality are recommended to redirect devices to LAS (sbc-las.ucaasnetwork.com) as a workaround. Another update will be provided by 4 PM ET."
15:23 EDT - Announcement in Discord - "oit_marissa (Chief of Staff) — 08/15/2023 3:23 PM
Major Incident Update: We're seeing marked improvements in network performance. QoS scores have also improved. We will continue to monitor as we work on finding the root cause. Our next update will be before 5 PM EST"
15:30 EDT - Call started with partner support for additional troubleshooting
16:45 EDT - We start seeing improved performance largely due to decreased call volume and overall load. The decision is made to investigate more and engage with additional partner support.
16:53 EDT - Accouncement in Discord - "oit_marissa (Chief of Staff) — 08/15/2023 4:53 PM
Major Incident Update: Our DC support has identified the cause of the latency from an upstream ISP. We are attempting to route around this ISP while they work to resolve the problem and will continue to monitor it. The next update will be provided by tomorrow 10 AM ET."
August 16, 2023
07:55 EDT - Start receiving new reports via Discord of the same issues from yesterday
08:00 EDT - Resume troubleshooting
12:00 EDT - OIT Resources hop on a call with the partner support team. Additional research and troubleshooting resulted in a call for restarting the NMS service
13:20 EDT - Announcement in Discord - "oit_simon (Communications) — Yesterday at 1:20 PM
Major Incident Update:
We have determined that there are network interface errors on GRR that are contributing to the packet loss and latency. While we continue to troubleshoot we have decided to take GRR offline. This will happen at 1:30 PM EST. Phones will failover to their alternate data centers. Manually configured phones using SRV records will also failover. Any devices manually configured with A records will need to be modified to point to alternate servers. Contact support if needed.
We will continue to provide updates as we learn more information. We appreciate your patience and understanding."
13:30 EDT - Ray initiates 503 from the server to divert traffic away
13:50 EDT - NMS service restarted
14:15 EDT - Resources look appropriate and isolate root cause: Runaway proxy thread consuming CPU resources causing slow performance and leaving multiple stuck calls in memory
15:00 EDT - Join conference call with partner services for additional RCA and performance tweaking
15:08 EDT - 503 removed and traffic is slowly shifted back. Monitoring metrics show within acceptable parameters
13:49 EDT - Announcement in Discord - Final update - "oit_garrett - (Tech Manager) — Yesterday at 3:49 PM
Major Incident Update:
We have finished the emergency maintenance on GRR and are seeing significant improvement on the network interface of GRR. As of 3:15 PM EST, GRR has resumed service. All clients should see inbound calls properly connecting and any remaining registrations reconnect. We are continuing to work on GRR & LAS with DC support staff to improve functionality; as well as next steps to prevent this further.
Contact support if needed. We will continue to provide updates as we learn more information. We appreciate your patience and understanding."
Root Cause
The root cause was identified as a runaway process within NMS services, specifically a thread of the NMS Proxy Worker. This means that a system process was stuck looping on itself for unknown reasons. As this was only a single thread affected, only some calls were impacted directly. However, due to this thread consuming an entire core of the system, other services were impacted by the increased wait times and thus further compounding more connectivity and performance issues.
At the time of the incident, there were no outstanding or known bugs or issues to date that matched the root cause.
See attached graphic for utilization of the worker thread compared to others on the system. 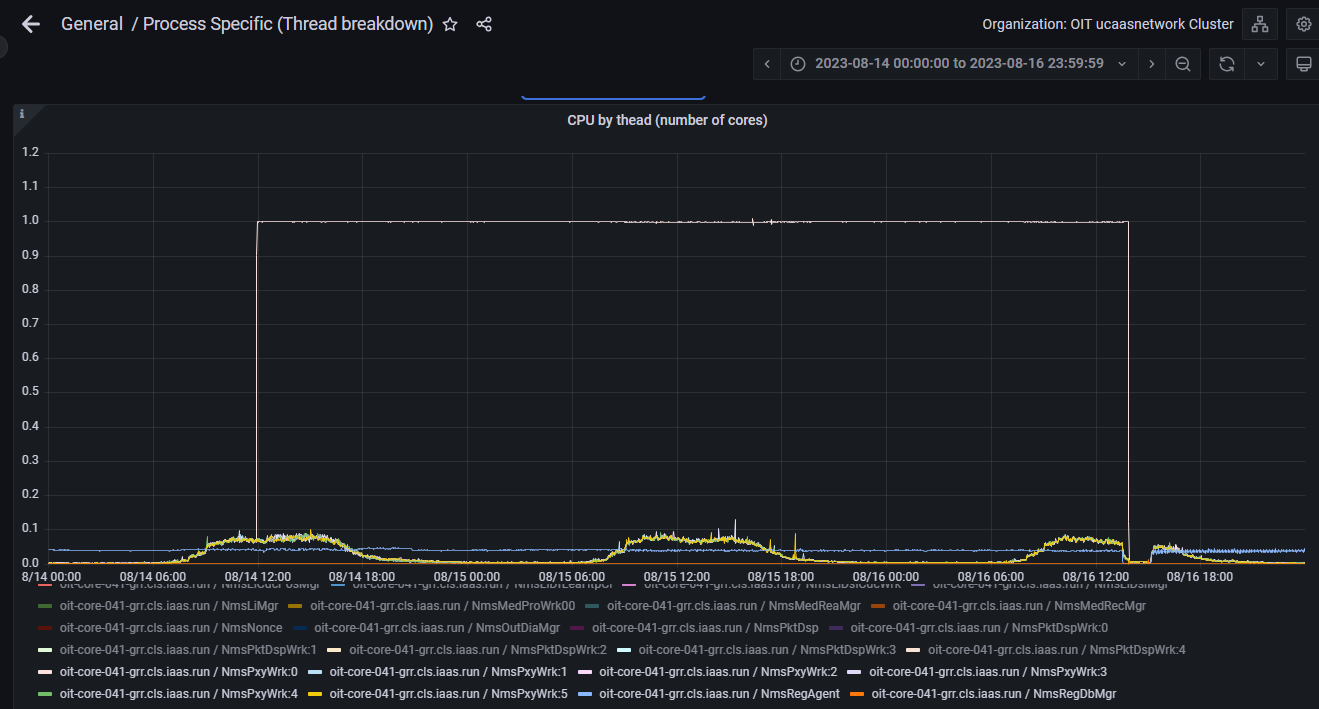
Future Preventative Action
- A patch was applied to prevent this condition again
- Our platform provider has implemented system-wide monitoring and alerting for this specific type of error